公示时间:2025年2月14日至2月18日
公示内容:
一、项目名称
高维复杂结构数据的统计学习理论与快速算法
二、提名者
重庆市沙坪坝区人民政府
三、提名等级
自然科学奖二等奖
四、项目简介
高维复杂结构数据的建模一直是统计学和机器学习领域中的研究热点和难点话题,其研究的进展也关系着诸多实际问题的预测效果和解决效率。针对具有变量强相关性、网络结构相关性、样本异常以及信息密度低的高维复杂结构数据,重庆大学、中央财经大学、重庆师范大学、成都理工大学和湖南工商大学组成科研联合团队,在国家自然科学基金面上项目的支持下,围绕高维复杂结构数据的统计学习理论和快速算法得到了一系列原创度高、代表性强、理论与应用价值兼备的科研成果,并已产生了一定的学术影响力。
本项目的创新研究内容主要分为四点:第一,围绕样本分布异常的分类学习问题,构建并系列研究了几何非平行双平面支持向量机,首次提出违反约束相对容忍度的概念并给出了理论上界,在实证分析中取得优异的分类效果。第二,针对高维复杂数据高效求解的领域内痛点问题,设计了与假设模型无关的变量筛选算法并成功应用到随机森林模型中,能够显著提高求解大规模问题的效率。第三,面向样本异常和信息密度低的高维网络结构化数据,建立了能够同时进行重要因子提取和回归学习的稳健稀疏主成分回归模型,有效克服了传统两步法泛化性能差的问题。第四,基于网络结构相关性和多重结构相关性的高维数据预测问题,采取各类正则化以及结构平滑策略,提出高效回归学习模型并在金融预测和图像恢复中获得突出效果。
本项目具有若干较强洞察力的科学发现。例如:第一,首次提出违反约束相对容忍度的概念并给出了理论上界,深化对机器学习重要模型支持向量机性质的认识。第二,意识到前向迭代筛选策略的重要性,通过改进使之能够应用到参数和非参数模型的大规模变量筛选问题中。第三,发掘统计学中的正则化技术、大样本理论和稳健理论,从根本上改进现有机器学习模型,提高在高维复杂结构数据学习任务中的泛化表现。
本项目的科学价值较高。一方面,从模型上丰富了现有高维复杂结构数据学习的基本框架;一方面,从理论上拓展了现有统计学习理论体系的外延;另一方面,对处理金融数据预测、图像数据恢复以及医学数据诊断等学习任务给出了高效的方案和工具。
本项目的成果得到了同行的广泛引用、跟踪研究和高度评价。截至当前,代表性论文累计他引64次,得到了许多学者的高度肯定。例如,拉马努金学者Tanveer教授推广了违反约束相对容忍度理论并评价其刻画了支持向量机的基本性质;知名学者张小刚教授将所提出的模型应用到烧结状态识别问题中,认为其表现达到国际先进水平。
五、代表性论文专著目录
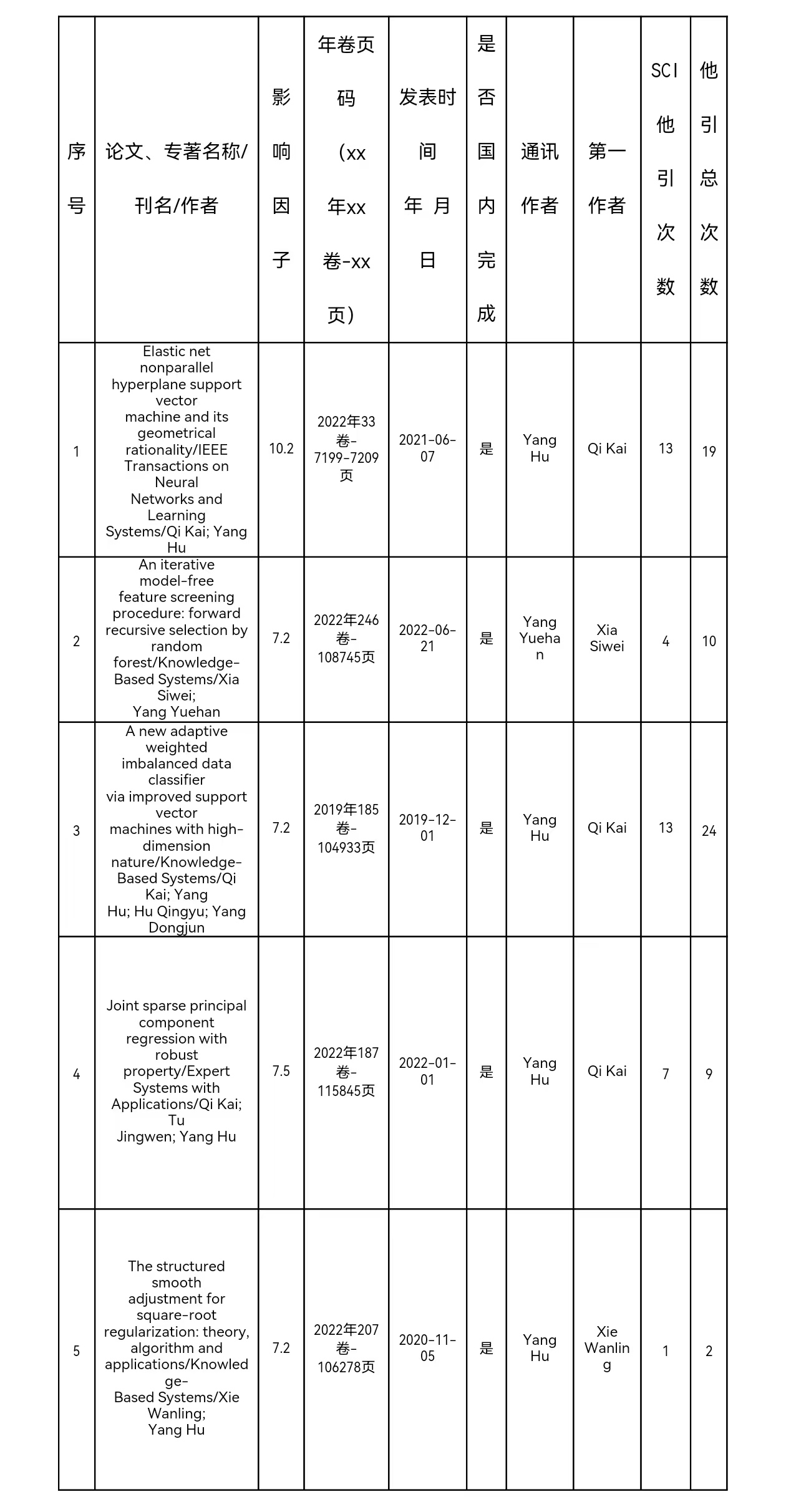
六、主要完成人
杨虎、杨玥含、齐凯、夏思薇、谢宛玲
七、主要完成单位
重庆大学,中央财经大学
联系人:刘晓宇、宋双权
联系电话:010-62288341
电子邮箱:kyc808@126.com
中央财经大学科研处
2025年2月14日
撰稿人:刘晓宇 审核人:王立勇

